[Sports] How K-means Clustering Could Help Recruit Soccer Players
##Contents
- Introduction
- BIG Player Hunter App Demo
- User Story
- Data
- Exploratory Data Analysis
- Feature Engineering
- K-Means clustering method
- Future Improvement
Introduction

Son Heung-min has every reason to be constantly smiling, and Tottenham has many reasons to be thankful. For a footballer so understated, so seemingly undemanding, Son has become indispensable for Tottenham. In last night’s game against Borussia Dortmund, Son scored his 9th goal in 11 games against Dortmund. In the 13 games Son has scored this season, Tottenham has gone on to win. - Chicago Tribune -
But what if Son gets a long-term injury or transfers to another team all of a sudden? Tottenham might want to find a player that resembles Son’s play style, which fits with the team’s overall strategy.
Successful recruitment is the lift blood of top performing sports teams. As in the story of Money Ball, some scouters don’t pay particular attention to statistics, but rather base decisions on their instincts. On the other hand, a manager like Oakland A’s general manager, Billy Beane would base his scouting decision on certain statistics.
If Tottenham were to lose a player like Son, the manager can use k-means clustering to find similarity between players, group them into clusters, and use filters to find players whose skill sets most resemble that of Son.
BIG Player Hunter App Demo
This is a demo of the BIG Player Hunter shiny application.
User Interaction story
Let’s take a second here to imagine how managers would find the app helpful.
Tottenham’s manager, Mauricio Pochettino, searches for players that most resemble Son Heungmin. Even though he has a hard time fully spelling Son’s name, the search box kindly generates a list of names he is possibly looking for. Ah! He clicks on “H. Son.”
He filters out a number of players he wants to see and bring the similarity bar to the lowest value to find the most similar players, then clicks the search button.
A total of 6 players, including Son, appears in the data table with each player’s basic information. After comparing the statistics of the players, he thinks to himself:
Well… These players all look fantastic, but I want a player who can commit to our team for the next 3-4 years at least. They all look pretty old at this point…
Pochettino adjusts the filters to search for more players, hopefully younger. Sorting the data table by age and position and looking at green dots on the plot, he stumbles upon a player who is 23 years old. His name is Bruno Fernandes. He types “bruno” in the data table and clicks on his profile photo which directs him to sofifa.com page for detailed information about the player Bruno Fernandes.
This guy looks pretty good at his age and definitely has a lot more room to grow! I will call the scout manager to look into him right now!

Data
Thanks to 4m4n5, I was able to download a nicely formatted csv dataset of players. The data contains over 85 attributes that describe their abilities from the latest edition of FIFA 2019 game.
The data contains self-explanatory attributes about each player as follows:

EDA
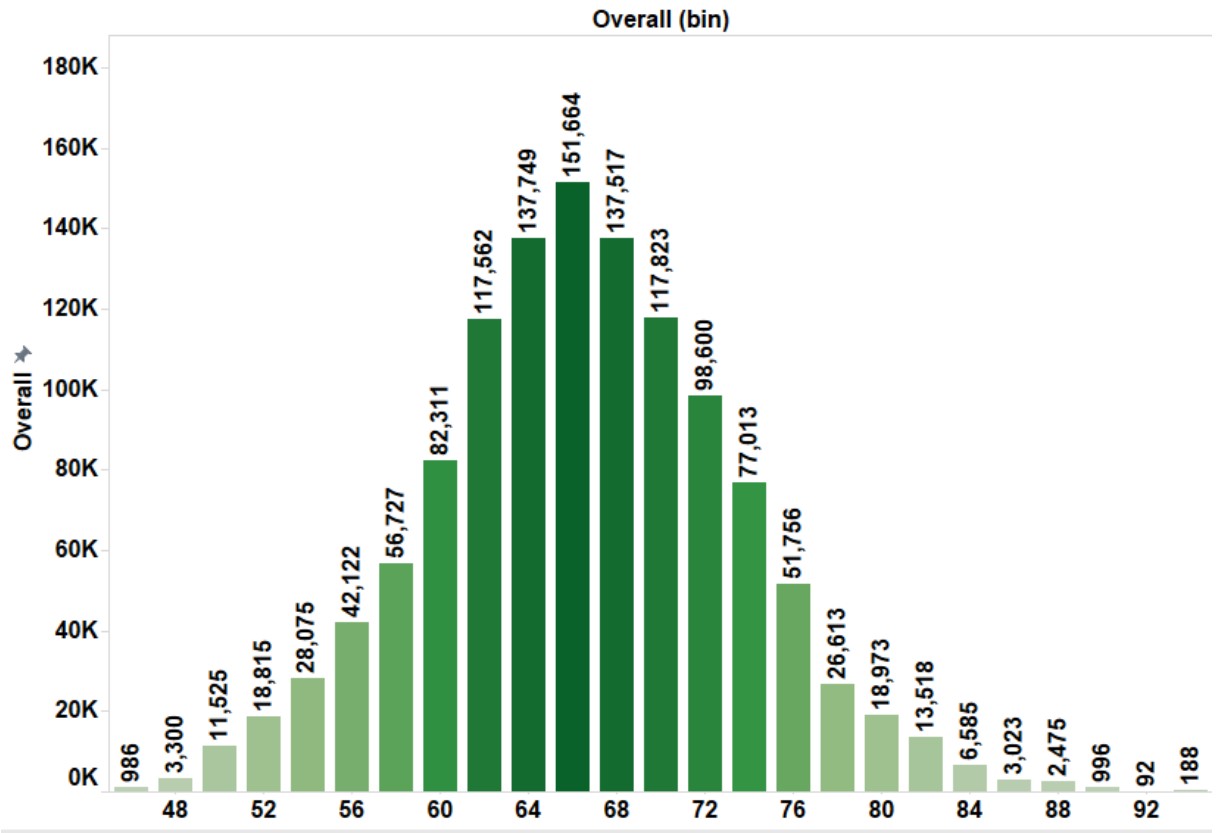
The overall ratings of players are normally distributed with a mean value at 66.
Overall rating Distribution
The overall ratings of players are normally distributed with a mean value at 66.
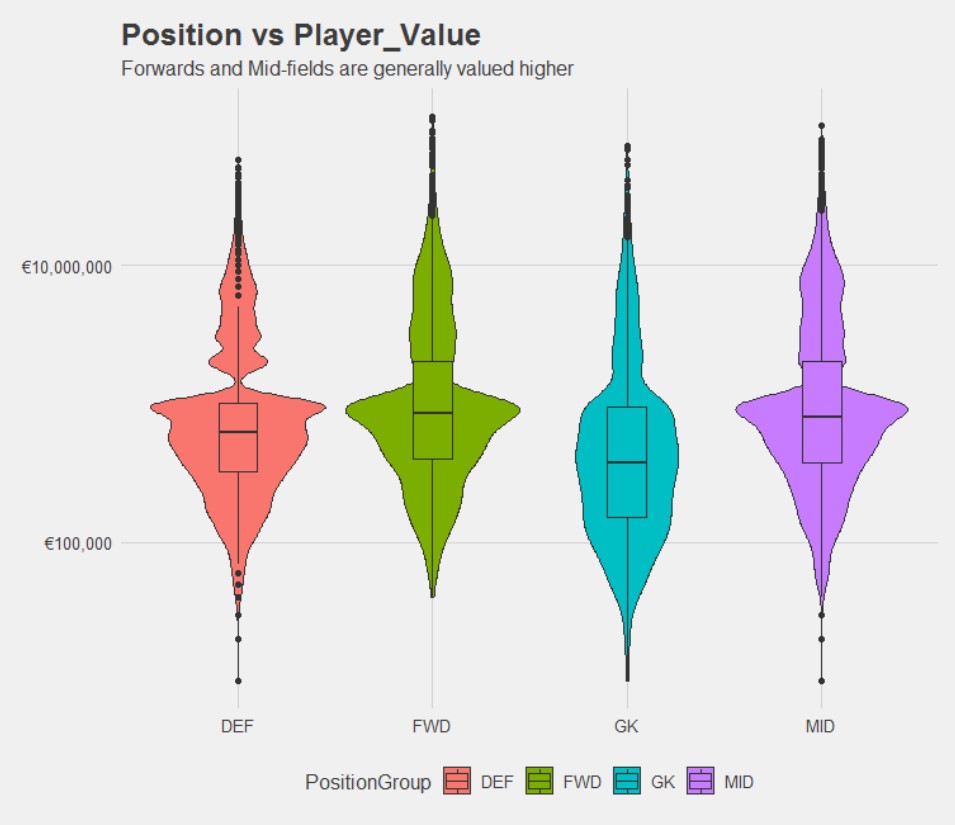
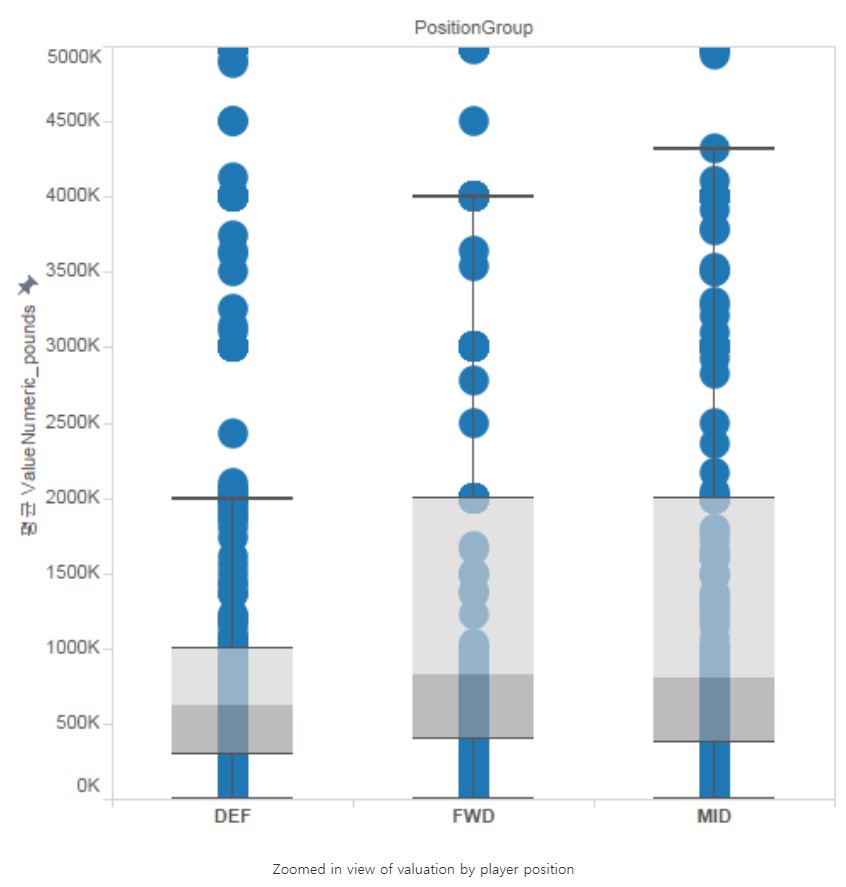
Valuation by position
Forwards and Mid-fields are generally valued higher. Specifically, Right Forwards, Left Forwards, and Right Attacking Mid-fields are valued the most.
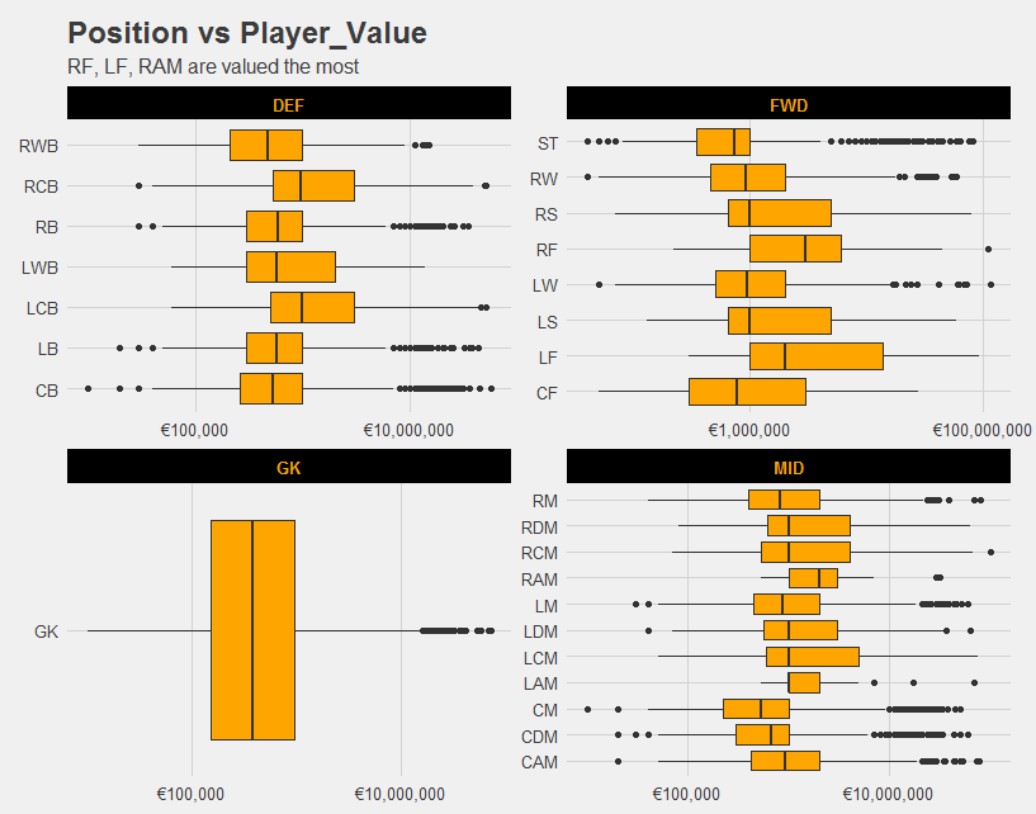
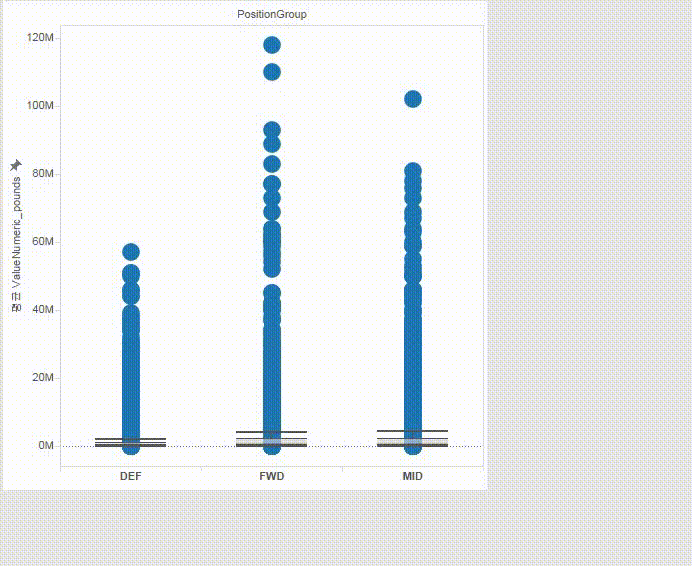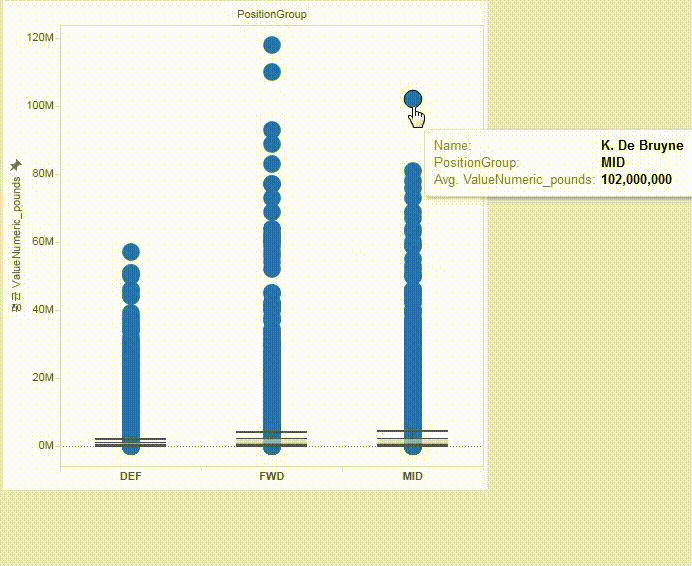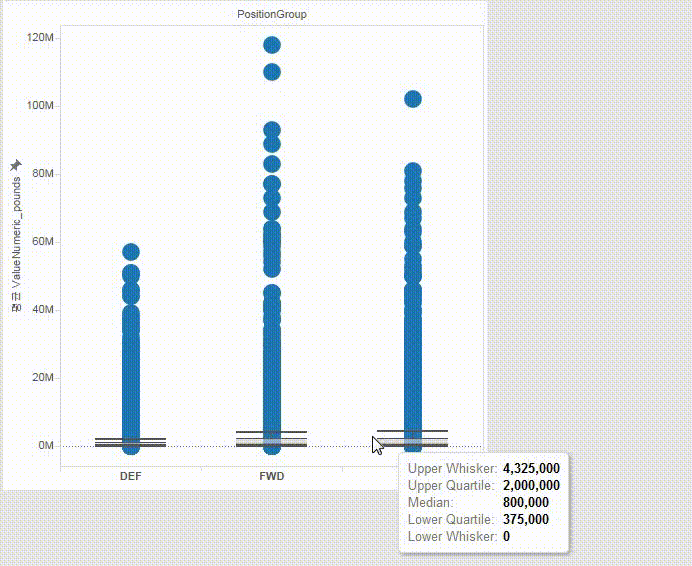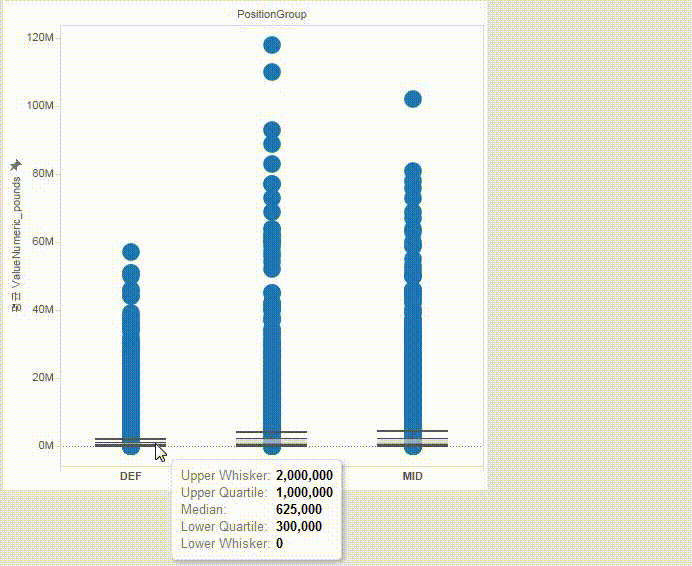
The heavy skewness is largely due to superstars like Messi, Ronaldo, Neymar, etc.
Correlation with Overall rating
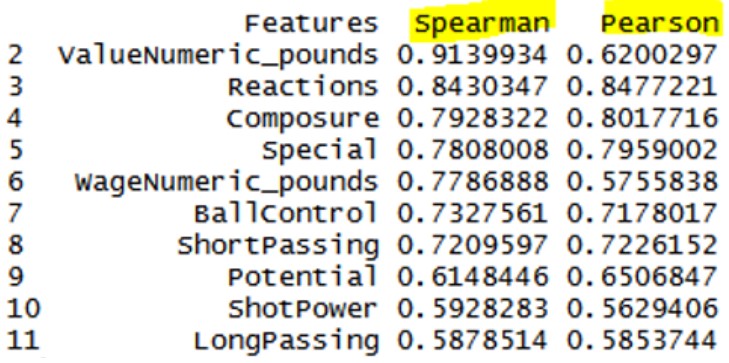
Above, the matrix data shows the correlations between the Overall rating and other key attributes for all players except goalkeepers. As we have already seen in the box and whisker plots, the data contains extreme outliers (superstars with astronomical valuation). The Spearman correlation method is more robust with dealing with outliers which explains why the Player Valuation has the highest correlation followed by Reactions, Composure, Special, and Wage. The Pearson method, on the other hand, generates different results with Reactions, Composure, Special, ShortPassing, and BallControl rounding out the top 5 correlated variables with Overall rating.
Feature Engineering
Some feature engineering was necessary for further analysis:
- Value ==> ValueNumeric_pounds
The raw data had value and wage of players as a character string with either K, M at the end of numeric values. I used regex to create numeric variables named ValueNumeric_pounds and WageNumeric_pounds
- Position ==> PositionGroup
Players were grouped into 28 different positions. I created four groupings: GK, DEF, MID, and FWD.
- Finishing + Longshots + Penalties + Shotpower + Positioning ==> AttackingRating
I created a new variable “AttackingRating” by taking the average of 5 attributes (Finishing, Longshots, Penalties, Shotpower, Positioning).
K-Means Clustering Method
The steps of making a k-means clustering model are as follows:
Filter out Goalkeepers and any players without a position listed
Omit data like player value, wages, and overall rating so that these variables don’t sway our groupings and allow for the clusters to contain similar players based on their skill sets
Feature engineer the data.
Scale the data.
Run k-means by looping through a number of cluster centers to find the optimal number (k). We can select the point where the elbow “bends” in a plot, or where the slope of the within groups sum of squares levels out.
Set the number of clusters based on where the curve bends in the plot, which in our case was k=8.
Re-run the model with k=8
Assign the cluster group back to the main data
From the data set, I used the following attributes to construct clusters using the k-means method:
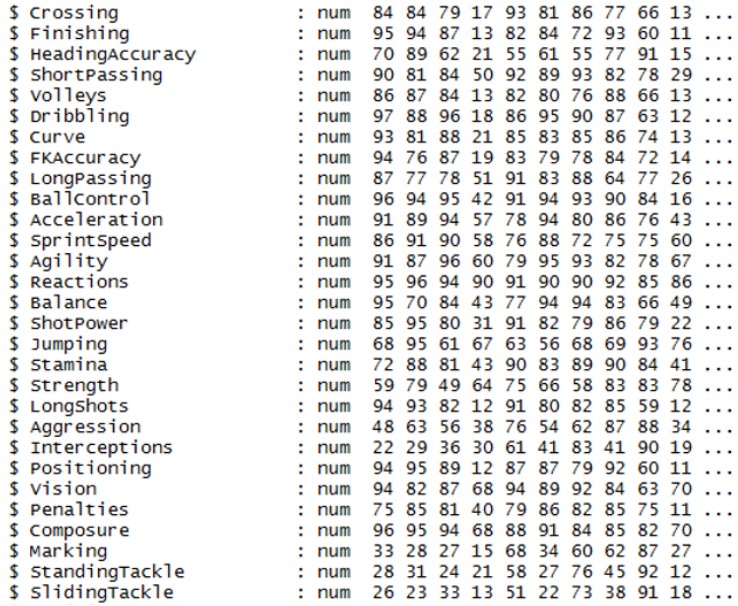
Note that I filtered out Goalkeepers in my clustering, and therefore had to exclude attributes that are specifically related to Goalkeepers, such as GKDiving, GKHandling, GKReflexes, etc.
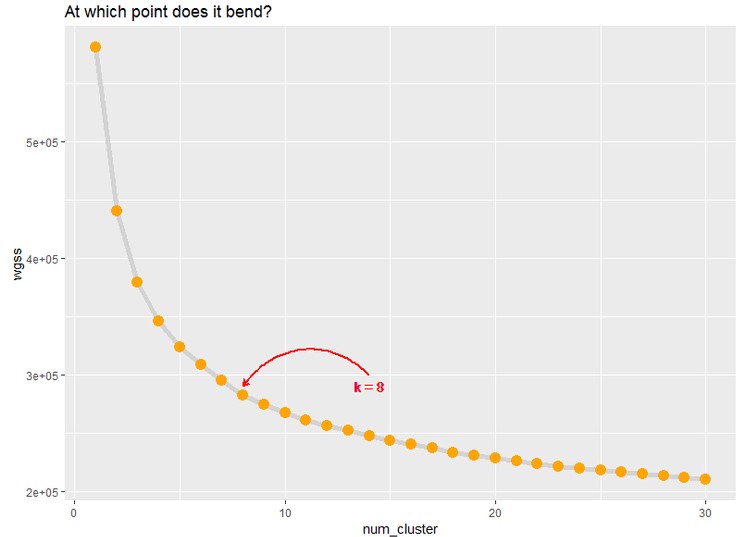
One may wonder how to choose a “good” k for k-means clustering. In other words, how many clusters do I know I want to split into?
In general, there is no method for determining the exact value of K, but an accurate estimate can be obtained using the following techniques.
One of the metrics that is commonly used to compare results across different values of K is the mean distance between data points and their cluster centroid. Since increasing the number of clusters will always reduce the distance to data points, increasing K will always decrease this metric, to the extreme of reaching zero when K is the same as the number of data points. Thus, this metric cannot be used as the sole target. Instead, mean distance to the centroid as a function of K is plotted and the “elbow point” where the rate of decrease sharply shifts, can be used to roughly determine K (see plot above).
A number of other techniques exist for validating K: cross-validation, information criteria, information theoretic jump method, silhouette method, and the G-means algorithm.
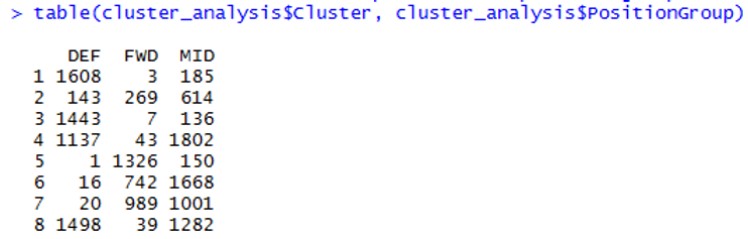
Each cluster contains 3 positions of players as in the snapshot shown above.
Cluster 4 seems to contain Defensive Mid-fields like Sergio Busquets, while Cluster 6 contains Attacking Mid-fields like Luka Modric and Mesut Ozil.
Cluster 1 & 3 contain Defenders, and cluster 2 is for Mid-fields, while cluster 5 is for Forwards.
It was very interesting to find that Cluster 2 contained players from all three positions that are relatively balanced. This is where superstars and game changers like Messi, Ronaldo, and Neymar are grouped in.
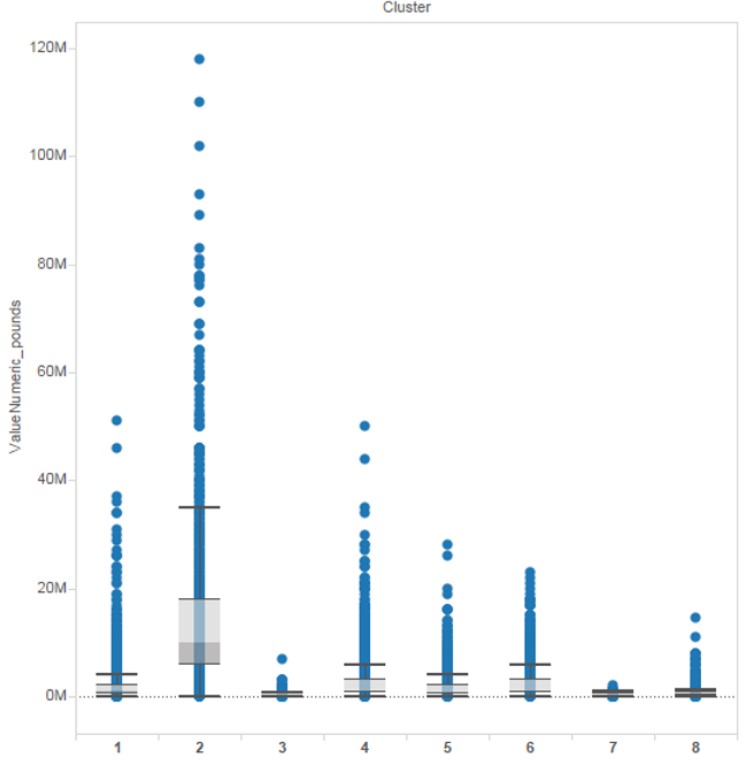
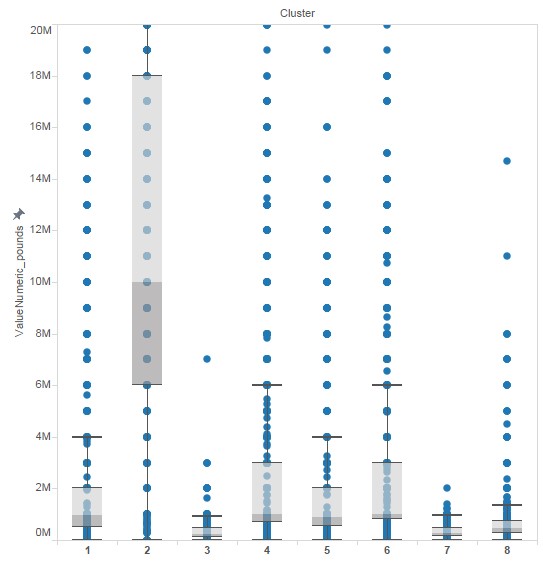
The box and whisker plots below show the range of player valuation for each cluster:
Future Improvement
As of May 2021, looking back to my previous project…
This post was written in March 2019 before Bruno Fernandes moved to Manchester United. In 2020-21 season (as of 050521), Bruno Fernandes has had 16 Goals 11 Assists in 34 Matches, while Heungmin Son has had 16 Goals 10 Assists in 33 Matches. Both of them are doing phenomenal jobs!
However, I realized that Bruno Fernades has a quiet different play style than that of Son. So I thought taking into account of the heatmap of players may result in better outcome for K-means clustering!
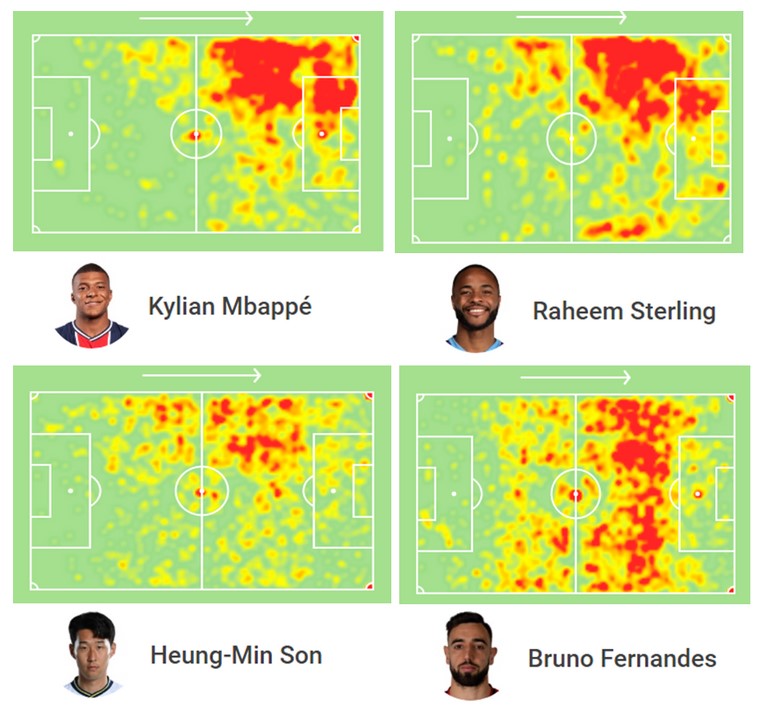
As shown above, Mbappe and Sterling are playing on the left majority of the time, while Fernandes evenly covers all over the ground like a center midfielder.
I was not able to access heatmap data in FIFA, but Bepro11, a soccer analytics company that films and tracks every player’s location during games, may have such data and be able to create a recruiting product for managers in the future. How exciting!
For those interested in soccer analytics through AI, please refer to the following article:
- https://deepmind.com/blog/article/advancing-sports-analytics-through-ai