[Internship] Data Science Internship Project: Predicting bounce load in logistics industry
Contents
3PL Business Model & Project Background
3PL (3rd Party Logistics) is a middle-man between a Customer A (who wants to get an item delivered from point A to point B) and a Carrier X (who owns transportation such as rails, ships, trucks, airplanes, etc.).
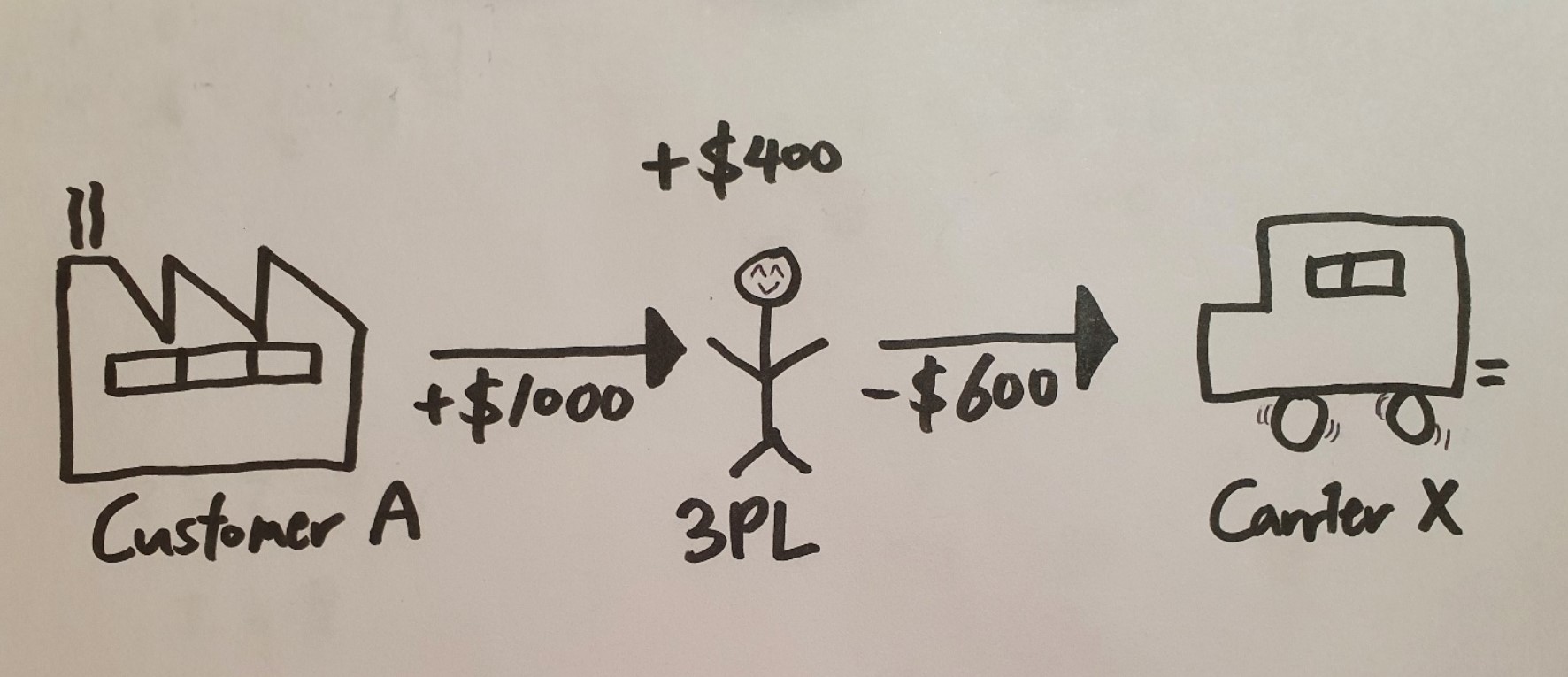
For example, let’s say that an frozen yogurt company (Customer A) wants to deliver their product from Austin, TX to Raleigh, NC. Customer A makes a contract with 3PL to deliver the product or “load” for $1000. The sales rep, Kelly, at 3PL, inputs the load information, such as pick up time, arrival time, departure location, destination, load type, product type, etc. to the software, which generates a list of refrigerated container trucks (Carrier X, Carrier Y, Carrier Z) that will be nearby Austin, TX to deliver the load. Kelly calls each carriers from the list and negotiates delivery price. Although Carrier Z offers the lowest price for delivery, Kelly is hesitant with Carrier Z’s capability. Rather, Kelly makes a contract with Carrier X at $600 who has successfully delivered similar loads in the past. This will leave Kelly with a total of $1000 - $600 = $400 profit.
BUT, something bad happens at the very last minute.
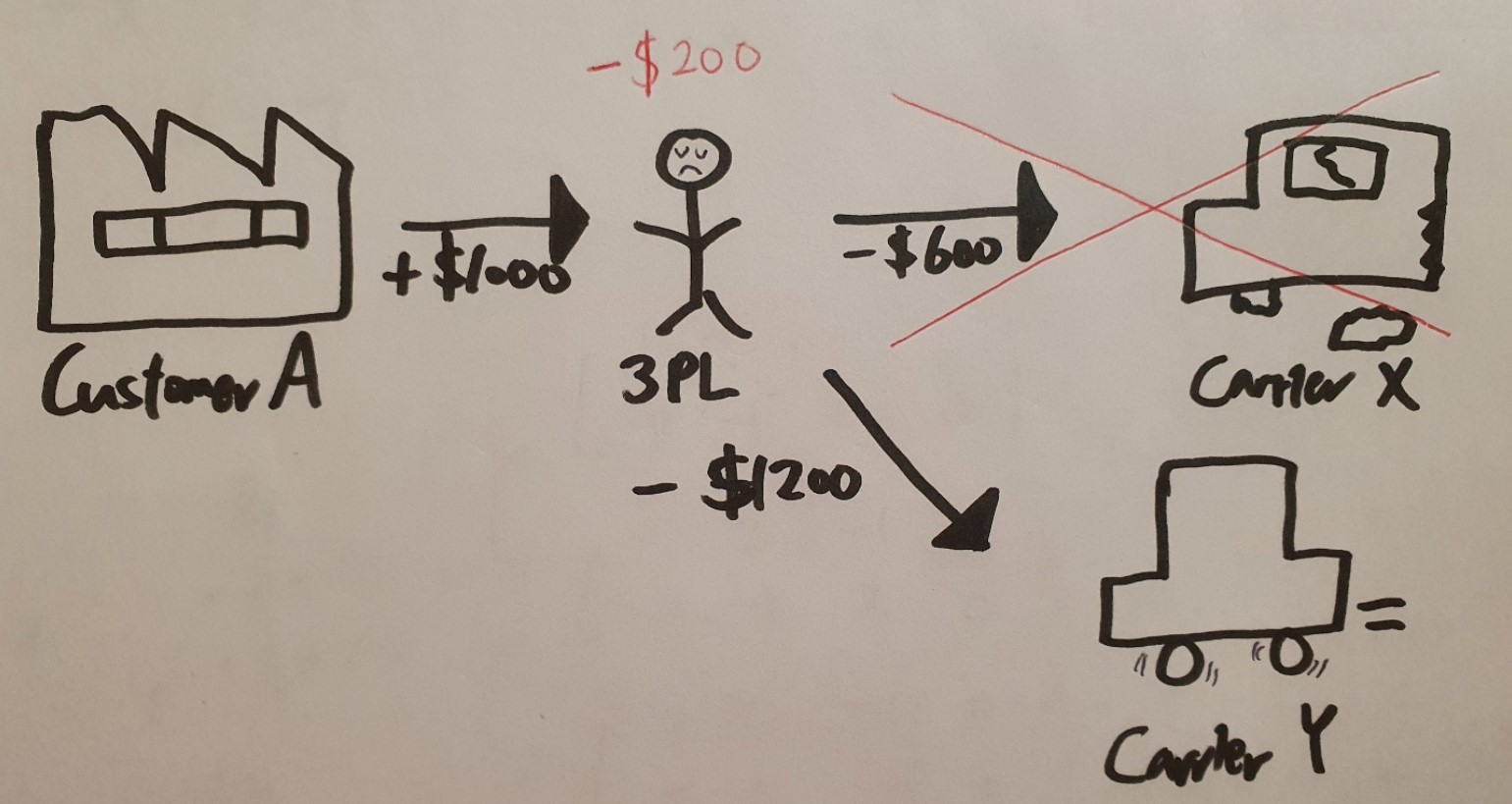
Four hours before the appointed pick up time, the Carrier X notifies Kelly that he can’t arrive on time to Austin and gives up to deliver the load due to many possible reasons: he ran late to the previous delivery location, an unexpected car accident broke out, he exceeded his total driving hour limit by law, and so on. This type of load that is firstly appointed to a carrier and later cancelled is called a “bounce load.” Kelly now has only 4 hours to find another carrier to deliver the load. If Kelly cannot to deliver the load on time, she will have to pay a penalty to Customer A for not complying with the contract which can also hurt the business relationship. With the urgent deadline, Kelly finds a carrier who agrees to deliver the load at $1200. Although this will leave no profit to Kelly, she can do nothing but make a contract with a deficit of $200.
- Due to the abrupt bounce load, Kelly is likely to:
- Make a contract with a new carrier at a higher price (lower margin)
- Damage customer relationship and pay late penalties if she fails to deliver the load on time
What if Kelly could prevent the bounce load in the first place? What if she foresaw that Carrier X was likely to bounce the load and made a contract with Carrier Z in the first place who would have successfully delivered the load?
Making these predictions come true was my summer project.

Project Goal
Based on the data including carrier’s information, weather, etc., our goal is to predict the probability of bounce rate of carriers and select the one with the lowest bounce rate to prevent costs occurring from bounce loads, thereby maximizing profits.
Project Workflow
- Data collection and cleaning
I utilized stored procedure and wrote a SQL script to collect 3.5 million loads. In order to feature engineer variables that might be important for predicting bounce loads, I asked around sales representatives as well as other professionals to gain domestic knowledge.
For instance, there is a regulation in the US that prohibits drivers from driving more than certain amount of hours consecutively. I talked to my manager to see if we are storing data like this and if not, if there’s any ways we could access those information.
In addition, since the data was imbalanced, I used SMOTE to raise bounce loads (minority class) by creating synthetic non-duplicate samples of the bounce loads.
- Model selection and building a random forest Model
Based on the models provided by scikit-learn library, considering the characteristics of features (multi-collinearity, variance, etc.) as well as the explainability of feature importance on the model, I decided that random forest is the most appropriate.
First of all, I used under-sampling method in order to account for the small ratio of the number of bounce loads to the total number of loads and split the data into training and test dataset 80:20 respectively. I used Bayesian Optimization to tune some hyper-parameters to increase the model’s performance.
At first, the model was built upon the default threshold = 0.5, but I found the optimal threshold to minimize the recall [TP/(TP+FN)]. Due to the characteristics of the project, minimizing the FN rate was more than than FP rate or accuracy.
- Cost Benefit Analysis
Let’s say that our predictive model tells us that Carrier X and Y will deliver the load for $700 vs. $500 with a success rate of 0.90 vs. 0.80. Which Carrier should we choose? I carried out a CBA for such a case.
If an increase in 0.01 success rate incurs $5 of profit, Carrier Y is likely to deliver the load at (0.90 – 0.80) / 0.01 * 5 + $500 = $550; therefore, it’s more rational to choose Carrier Y over Carrier X. However, this is a simplified example, and we should be aware that the profit is not always linear to the success rate and is subject to change depending which interval of success rate we are looking at.
- Web Application Development & Data Pipeline
I constructed a live data pipeline on > 3.5 million loads using a message queue called ZeroMQ in order to make sure that our data isn’t lost on the way to arriving at the server side for predictive analysis.
The prediction result is then sent back to the demo web application, which I developed to earn buy-in from potential stakeholders.
Below is the data flow of the service:
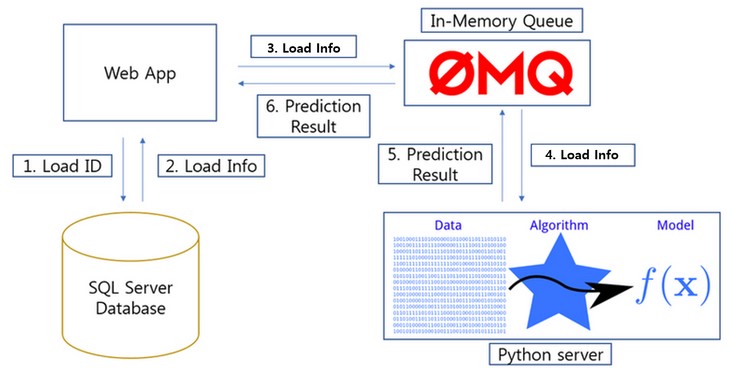
- User types in a LoadID on the Web which triggers the Web App (Client) to retrieve information about of the load from the database.
- Send load information to the server (where predictive model is) through the message queue.
- Send delivery success rate of carriers to the Web App (Client)
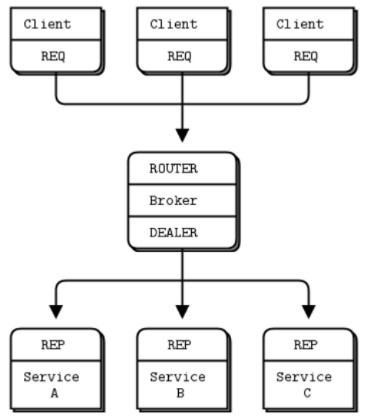
In regards to the message queue, I used a request-reply broker that makes the client/server architectures easier to scale because clients don’t see workers, and workers don’t see clients. The only static node is the broker (ZeroMQ) in the middle.
In regards to the message queue, I used a request-reply broker that makes the client/server architectures easier to scale because clients don’t see workers, and workers don’t see clients. The only static node is the broker (ZeroMQ) in the middle.
Risks
If sales reps were to follow the model’s prediction 100%, the expected savings per week was approximately $140,000.
However, I understand that it’s very difficult to build trust with the users, and if they were not following the model’s prediction 100% of the time, the total savings is subject to change.
Before fully releasing the Bounce Prediction Service into production, we might want to run an A/B Testing on the sales reps who are and aren’t referring to the model’s predictive suggestion and compare costs incurred from each group. In addition, we will need to check how sales reps feel about the model’s suggestion and collect the user experience data in order to make the adaption more smoothly.
In Retrospect
The 12 week long process of making a product from the scratch taught me that “domain knowledge” and “communication” are essential to being a good data scientist. It was a blast talking to people from different backgrounds in business, learning about features for predictive model, and coming up with new features to be engineered to improve our model. I found myself deeply immersed in the project and really enjoyed the time with other interns as well.
One thing I wish I had done during the internship was being involved with productionizing the product and carrying out A/B testing to observe how users react. I wish I had an experience of how A/B testing is done in the industry, how they collect user feedback and reflect it to the final release.
I really appreciate my manager, colleagues, sales reps, and intern friends who helped me throughout the journey. Especially, I’d like to thank my manager who granted me permission to a variety of data and supported me. Everyone was very willing to take time to answer my questions and put up with my curiosity. I learned not only the technical skills to become a good data scientist, but I also really cherish the opportunity to think about how important it is to build good relationship with my colleagues with whom I spend 1/3 of my day!
These are some of the thoughts I started to have in mind:
- How can I be helpful to people around me not just career-wise but life in general.
- How can I grow with people around me?
- What should I do now to do that?
I will constantly crave for finding answers to these questions.